- Published on
Ubuntu安装Spark
- Authors

- Name
- Lif
Spark
要处理一个.parquet数据,查了一下需要用到Pyspark。简单的记录一下安装过程。
记录的原因是,官方文档对于不用JAVA的我真的很难理解。我相信不只我一个人会这样认为!
依赖
- 使用
Pyspark需要安装spark - 安装
Spark需要安装Java JDK - 也许也会用到
Hadoop,这个可装可不装 - ubuntu系统(个人依赖,可以换成其他系统)
安装JDK
# 在linux安装java
$ sudo apt-get update # 也可使用apt sudo apt update
$ sudo apt-get install openjdk-17-jre-headless
# 如果是ubuntu系统,直接输入java,如果有就不用安装,如果没有会提示多个版本的安装指令,复制过来直接安装即可
# 只按最新的,不安最稳的
# 获取Java路径
$ sudo update-alternatives --config java
$ sudo vim /etc/environment
# 将获取到的路径写入environment
# 例如 JAVA_HOME="/usr/lib/jvm/java-17-openjdk-amd64"
$ source /etc/environment
安装Spark
Spark的安装通过官方的压缩包安装比较简单,点击下载页面, 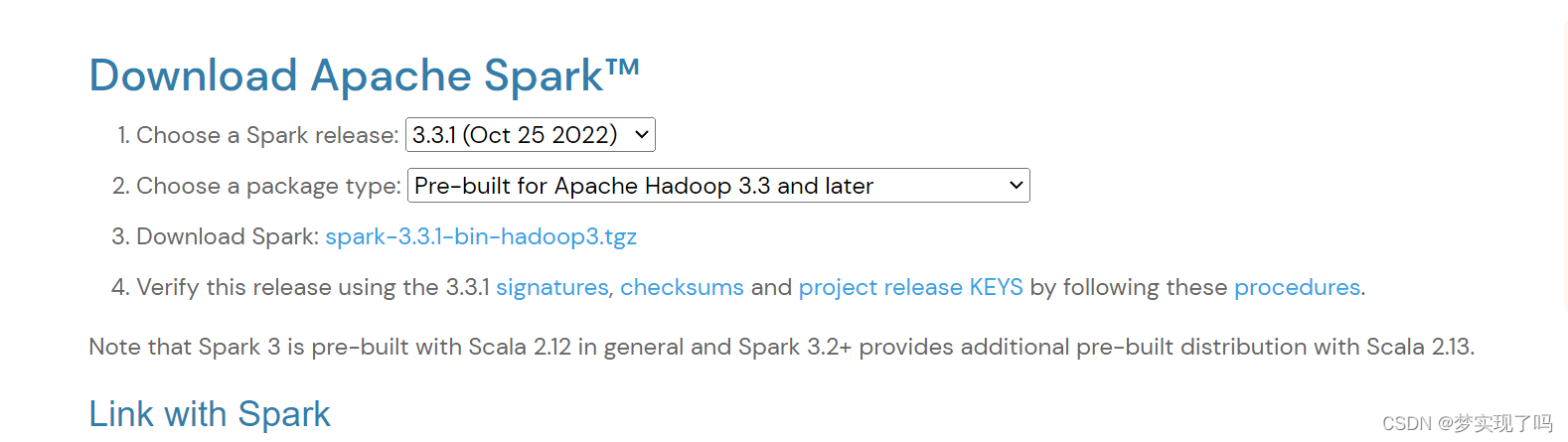 选择一个即可,这里我选择最新版本的。 下载完成后转移到
选择一个即可,这里我选择最新版本的。 下载完成后转移到Ubuntu系统里
# 类似命令如下
$ scp file root@host:/path
# 如果linux网速够快可以直接在linux下载,两种方法取一个即可
$ wget https://www.apache.org/dyn/closer.lua/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
然后切换到目标目录,解压
$ tar -zxf .\spark-3.3.1-bin-hadoop3.tgz
$ sudo mv spark-3.3.1-bin-hadoop3 /usr/local/spark
$ export PATH=$PATH:/usr/local/spark/bin # 这个可能不会生效
$ source ~./bashrc # 这个可能不会成功,这两个关系不大
$ cd /usr/local/spark
$ bin/spark-shell # 如果配置好JAVA_HOME即可开启,没有Hadoop会报警